eBPF: From Kernel to Cloud, Episode 6
What Is eBPF? · The BPF Verifier · eBPF vs Kernel Modules · eBPF Program Types · eBPF Maps · CO-RE and libbpf**
TL;DR
- Kernel structs change between releases — hardcoded offsets break across patch versions, not just major releases
- BTF embeds full type information in the kernel at
/sys/kernel/btf/vmlinux; CO-RE uses it to patch field accesses at load time
(BTF = BPF Type Format — a compact description of every struct, field, and byte offset in the running kernel, built into the kernel image) vmlinux.h, generated from BTF, replaces all kernel headers with a single file committed to your repositoryBPF_CORE_READ()is the CO-RE macro — every kernel struct access in a portable program goes through it- libbpf skeleton generation (
bpftool gen skeleton) eliminates manual fd management for map and program lifecycle - For production tools: libbpf + CO-RE. For one-off debugging: bpftrace. For prototyping: BCC.
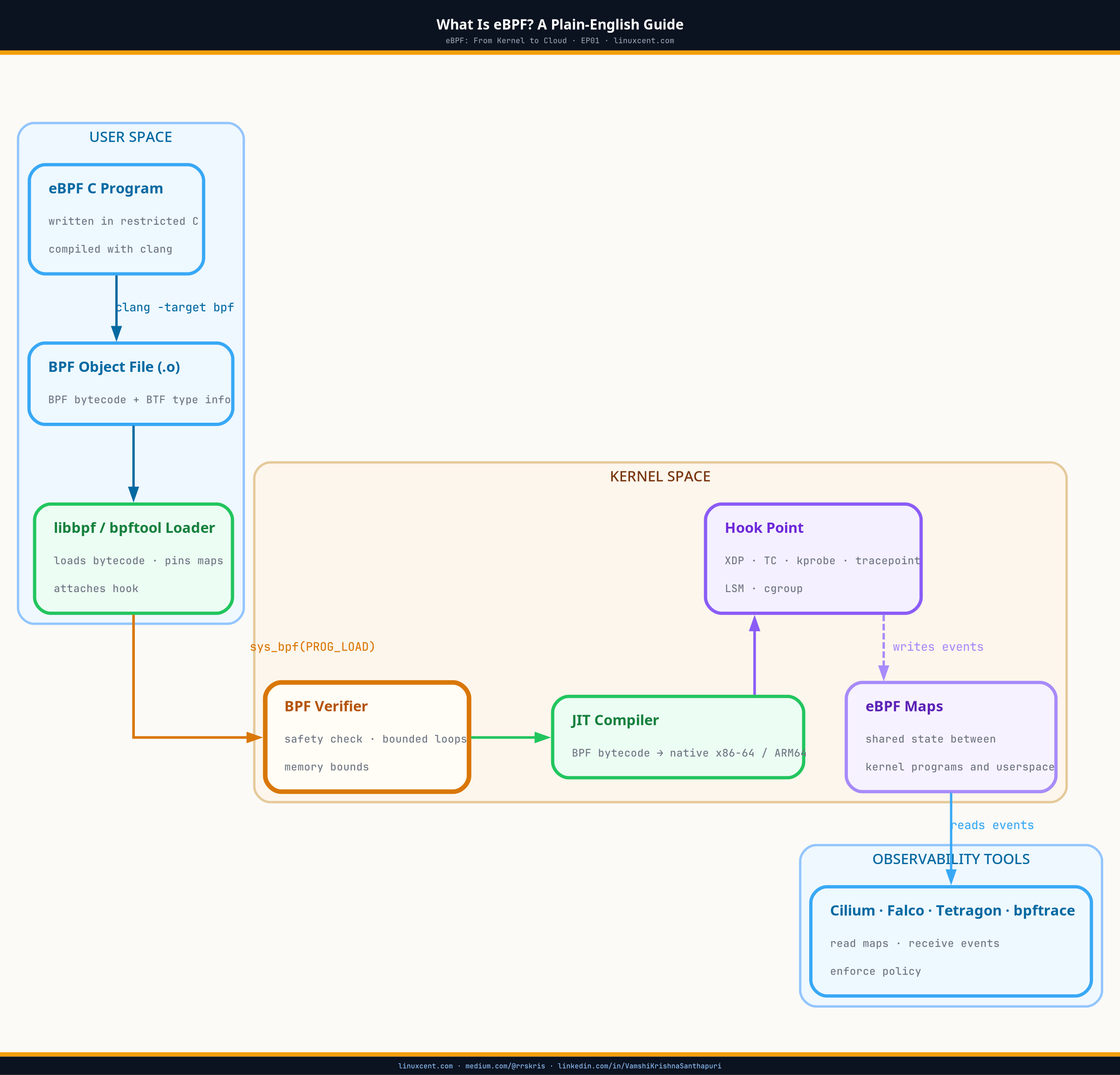
eBPF CO-RE (Compile Once, Run Everywhere) solves the kernel portability problem — the reason Cilium and Falco survive kernel upgrades without recompilation. What maps assumed — quietly — is that the kernel structs those programs read look the same tomorrow as they do today. They don’t. The Linux kernel has no stable ABI for internal data structures. task_struct, sk_buff, sock — the fields eBPF programs read constantly — can shift between patch releases, not just major versions. I learned this the hard way when a routine upgrade from 5.15.0-89 to 5.15.0-91 — two patch revisions — silently broke a custom tracer I’d been running in production for six months.
Six months after deploying a custom eBPF tracer for a client — it detected specific syscall patterns that Falco’s default ruleset didn’t cover — they ran a routine Ubuntu patch upgrade. Not a major kernel version jump. 5.15.0-89 to 5.15.0-91. Two patch revisions.
The tracer stopped loading. The error was invalid indirect read from stack. I opened the program source: nothing remotely like an indirect read. The program was a straightforward tracepoint handler, maybe 40 lines of C.
Three hours of debugging led to a four-byte offset difference. The struct task_struct had a field alignment change between the two patch versions. My program accessed ->comm at a hardcoded byte offset. On 5.15.0-89 that offset was 0x620. On 5.15.0-91 it was 0x624. The verifier caught the misalignment — correctly — and rejected the program.
I had compiled the eBPF bytecode against a fixed kernel header snapshot. The binary was not portable. Every time the kernel moved a struct field, the tool broke.
CO-RE is the solution to this.
Quick Check: Does Your Cluster Support CO-RE?
Two commands — check whether your nodes have the BTF support that CO-RE tools require:
# SSH into a worker node, then:
ls -la /sys/kernel/btf/vmlinux && echo "BTF available — CO-RE tools will work"
Expected output on a supported node:
-r--r--r-- 1 root root 4956234 Apr 21 00:00 /sys/kernel/btf/vmlinux
BTF available — CO-RE tools will work
If the file is missing: CO-RE tools (Cilium, Falco, Tetragon) will fall back to legacy BCC compilation mode — which requires a full compiler toolchain and kernel headers installed on every node.
# Confirm the kernel was built with BTF enabled
cat /boot/config-$(uname -r) | grep CONFIG_DEBUG_INFO_BTF
# CONFIG_DEBUG_INFO_BTF=y ← required for CO-RE
Common results by platform:
| Platform | BTF available? |
|———-|—————-|
| Ubuntu 20.04+ (kernel 5.4+) | ✓ Yes |
| EKS managed nodes (AL2023) | ✓ Yes |
| GKE managed nodes (kernel 5.10+) | ✓ Yes |
| Amazon Linux 2 (older kernels) | ✗ No — BCC fallback |
| RHEL 7 / CentOS 7 | ✗ No |
Why Kernel Structs Change and Why It Matters
The Linux kernel has no stable ABI for internal data structures. task_struct, sock, sk_buff, file — the structs that eBPF programs read constantly — change between releases.
ABI (Application Binary Interface) is the contract that says a compiled binary built against version N will still work against version N+1 without recompilation. The Linux kernel maintains a stable ABI for syscalls (
open(),read(),connect()) but makes no such guarantee for internal structs. Fields move, get added, get renamed between patch releases — and any program with hardcoded offsets silently breaks. Field additions, reordering, alignment changes, struct embedding changes. The kernel developers are under no obligation to preserve internal layouts, and they don’t.
Before CO-RE, eBPF programs dealt with this in two ways:
BCC (BPF Compiler Collection) — compile the eBPF C code at runtime on the target host, using that system’s kernel headers. No portability problem because compilation happens on the machine you’re deploying to. Cost: you need a full compiler toolchain, kernel headers, and Python runtime on every production node. Startup time in seconds. Container image size in hundreds of MB. For a security tool that should be lightweight and fast-starting, this is a non-starter.
Per-kernel compiled binaries — ship different builds for each supported kernel version, detect at runtime, load the matching binary. Falco maintained this model for years. The operational overhead is significant: a matrix of kernel × distro × version with separate build and test pipelines for each combination.
CO-RE is the third option. Compile once on a build machine, and let libbpf patch struct field accesses at load time on the target system, using type information embedded in the running kernel.
BTF: The Type System That Makes CO-RE Possible
BTF (BPF Type Format) is compact type debug information embedded directly into the kernel image. Since Linux 5.2, kernels built with CONFIG_DEBUG_INFO_BTF=y expose their full type information at /sys/kernel/btf/vmlinux.
# Verify BTF is available
ls -la /sys/kernel/btf/vmlinux
# Inspect the BTF for a specific struct
bpftool btf dump file /sys/kernel/btf/vmlinux format raw | grep -A 5 'task_struct'
# See the actual field offsets the running kernel uses
bpftool btf dump file /sys/kernel/btf/vmlinux format c | grep -A 20 'struct task_struct {'
BTF encodes every struct definition with field names, types, and byte offsets. When libbpf loads an eBPF program compiled with CO-RE relocations, it reads both the BTF the program was compiled against (embedded in the .bpf.o file) and the BTF of the running kernel. If task_struct->comm has moved, libbpf patches the field access instruction before loading the program.
This patching happens at load time, transparently, without modifying the binary you shipped.
CO-RE relocation is the mechanism behind this. When a CO-RE program is compiled, it embeds metadata saying “I need the offset of
comminsidetask_struct” rather than hardcoding0x620. At load time, libbpf reads this relocation, looks up the real offset from the running kernel’s BTF, and patches the instruction. For operators: this is why Cilium and Falco survive kernel upgrades without you reinstalling them.
Most distribution kernels now ship with BTF enabled:
# Ubuntu 20.04+ (kernel 5.4+)
cat /boot/config-$(uname -r) | grep CONFIG_DEBUG_INFO_BTF
# CONFIG_DEBUG_INFO_BTF=y
# Check at runtime
file /sys/kernel/btf/vmlinux
# /sys/kernel/btf/vmlinux: symbolic link to /sys/kernel/btf/vmlinux
Amazon Linux 2023, Ubuntu 22.04, Debian 11+, RHEL 8.2+, and most cloud-provider-managed kernels have BTF. The notable exception: RHEL 7 and Amazon Linux 2 on older kernels.
The CO-RE Toolchain
The build pipeline for a CO-RE eBPF program:
Development machine:
vmlinux.h (generated from kernel BTF)
↓
myprog.bpf.c ──── clang -target bpf -g ────→ myprog.bpf.o
(CO-RE relocations embedded in BTF section)
↓
bpftool gen skeleton myprog.bpf.o ─────────→ myprog.skel.h
↓
myprog.c (userspace) ── gcc ──→ myprog
(statically links libbpf, skeleton handles load/attach/cleanup)
Target machine (any kernel with BTF, 5.4+):
./myprog
↓ libbpf reads /sys/kernel/btf/vmlinux
↓ patches field accesses to match current kernel struct layout
↓ verifier validates patched program
↓ program loads and runs
One binary. Any supported kernel. No compiler on the target system.
vmlinux.h — One Header to Replace Them All
Before CO-RE, eBPF C programs included dozens of kernel headers — linux/sched.h, linux/net.h, linux/fs.h, linux/socket.h — and they had to match the exact kernel version you were targeting.
vmlinux.h is generated from the BTF of a running kernel. It contains every struct, enum, typedef, and macro definition the kernel exposes through BTF — in a single file, without any compile-time kernel dependency.
# Generate vmlinux.h from the running kernel
bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
# Typical size
wc -l vmlinux.h
# 350000+
You commit vmlinux.h to your repository, generated from a representative kernel. CO-RE handles the actual layout differences at load time on whatever kernel you deploy to. The file is large but you only generate it once and update it when you add support for a new kernel generation.
In your eBPF C source:
#include "vmlinux.h" // replaces all kernel headers
#include <bpf/bpf_helpers.h> // eBPF helper functions
#include <bpf/bpf_tracing.h> // tracing macros
#include <bpf/bpf_core_read.h> // CO-RE read macros
How CO-RE Fixes the Offset Problem
The mechanism is worth understanding once, even if you’re not writing eBPF programs.
When a CO-RE eBPF program accesses a kernel struct field, it doesn’t hardcode the byte offset. Instead, it records a relocation — “I need the offset of pid inside task_struct” — in the compiled binary. When libbpf loads the program, it resolves each relocation by looking up the field in the running kernel’s BTF and patches the access instruction to use the correct offset for this specific kernel.
This is why my four-byte problem happened: the tracer I’d compiled wasn’t using CO-RE. It hardcoded 0x620 as the offset of task_struct->comm. When the kernel moved it to 0x624, the program accessed the wrong memory, the verifier caught the misalignment, and the load failed. A CO-RE rewrite would have resolved comm‘s offset at load time from BTF and never known the difference.
The relocation model also handles fields that don’t exist on older kernels. If a program accesses a field added in kernel 5.15 and the running kernel is 5.10, libbpf can either skip the access (returning a zero value) or fail the load — depending on how the program marks the field access. This is how tools ship support for features across a kernel version range without separate builds.
What CO-RE Means for Tools You Already Run
This is why you care about CO-RE even if you’re never going to write an eBPF program yourself.
Falco, Cilium, Tetragon, and Pixie all ship as single binaries or container images. You install them on a Ubuntu 22.04 node, a RHEL 9 node, and an Amazon Linux 2023 node — three different kernel versions, three different task_struct layouts — and the same binary works on all of them. Before CO-RE, Falco maintained pre-compiled kernel probes for every supported kernel version in a matrix of distro × kernel × version. The probe list had thousands of entries. A kernel your distro shipped between Falco release cycles meant a gap in coverage until the next release.
With CO-RE, there’s one binary. libbpf reads the running kernel’s BTF at load time, patches the field accesses to match the actual struct layout, and the verifier checks the patched program. The tool vendor doesn’t need to know about your specific kernel. You don’t need to wait for a probe release.
The constraint is BTF availability. Check your nodes:
# Quick check — if this file exists, CO-RE tools work
ls /sys/kernel/btf/vmlinux
# Full confirmation
cat /boot/config-$(uname -r) | grep CONFIG_DEBUG_INFO_BTF
# CONFIG_DEBUG_INFO_BTF=y ← required
What you’ll find: Ubuntu 20.04+, Debian 11+, RHEL 8.2+, Amazon Linux 2023, and GKE/EKS managed nodes all have BTF. Amazon Linux 2 and RHEL 7 do not. If you’re running those, CO-RE-based tools fall back to the legacy BCC compilation path — which requires kernel headers installed on the node.
The One Thing to Run Right Now
This command shows you the exact struct layout your running kernel uses — the same layout libbpf reads when it patches CO-RE programs at load time:
# See how your kernel defines task_struct right now
bpftool btf dump file /sys/kernel/btf/vmlinux format c | grep -A 30 '^struct task_struct {'
The output is the canonical type information for your running kernel. Every field, every offset. When libbpf loads a CO-RE program, it’s reading this to figure out whether task_struct->comm is at offset 0x620 or 0x624.
You can also see specific struct sizes and verify that two kernels differ:
# On kernel A (5.15.0-89)
bpftool btf dump file /sys/kernel/btf/vmlinux format raw | grep -w "task_struct" | head -3
# On kernel B (5.15.0-91) — same command, different output if struct changed
# This is what broke my tracer: field offset changed across a two-patch jump
The practical use: when a CO-RE eBPF tool fails to load with a BTF error, this is where you look. The error tells you which struct field the relocation failed on. This command shows you the current layout. You can confirm whether the field exists, whether it moved, whether it was renamed.
BCC vs libbpf vs bpftrace
Three approaches to eBPF development, with distinct tradeoffs:
| BCC | libbpf + CO-RE | bpftrace | |
|---|---|---|---|
| Compilation | Runtime on target host | Build-time on dev machine | Runtime (embedded LLVM) |
| Target deployment | Compiler + headers on every node | Single static binary | bpftrace binary only |
| Portability | Compile-on-target handles it | CO-RE + BTF handles it | Internal CO-RE support |
| Memory overhead | High (Python + compiler: 200MB+) | Low (few MB binary) | Medium |
| Startup time | Seconds (compilation) | Milliseconds | Seconds (JIT compile) |
| Best for | Prototyping, development | Production tools, shipped software | Interactive debugging sessions |
| Language | Python + C | C (kernel) + C/Go/Rust (userspace) | bpftrace scripting |
For anything you’re shipping — an eBPF-based security tool, an observability agent, an open-source project — libbpf + CO-RE is the right choice. BCC is for prototyping before you commit to an implementation. bpftrace is for the 30-second debugging session on a live node.
The practical test: if you’re building something you’ll deploy as a container image or a package, it needs to be a self-contained binary with no build dependencies on the target system. That means libbpf.
Common Mistakes
| Mistake | Impact | Fix |
|---|---|---|
Direct struct dereference instead of BPF_CORE_READ |
Program breaks on any kernel struct change | Use BPF_CORE_READ() for all kernel struct field access |
Missing char LICENSE[] SEC("license") = "GPL" |
GPL-only helpers (most tracing helpers) unavailable | Always include the license section |
| vmlinux.h generated on a very old kernel | Missing structs added in newer kernel releases | Regenerate from the highest kernel version you target |
Forgetting -g flag in clang invocation |
No BTF debug info → no CO-RE relocations | Always compile with -g -O2 -target bpf |
| Hardcoding struct offsets as integer constants | Breaks silently on next kernel patch | Use BTF-aware CO-RE macros exclusively |
Key Takeaways
- Kernel structs change between releases — hardcoded offsets break across patch versions, not just major releases
- BTF embeds full type information in the kernel at
/sys/kernel/btf/vmlinux; CO-RE uses it to patch field accesses at load time vmlinux.h, generated from BTF, replaces all kernel headers with a single file committed to your repositoryBPF_CORE_READ()is the CO-RE macro — every kernel struct access in a portable program goes through it- libbpf skeleton generation (
bpftool gen skeleton) eliminates manual fd management for map and program lifecycle - For production tools: libbpf + CO-RE. For one-off debugging: bpftrace. For prototyping: BCC.
What’s Next
CO-RE makes eBPF programs portable across kernel versions. EP07 takes the next question: where in the kernel’s data path does it make sense to attach them?
XDP fires before the kernel has allocated a single byte of memory for an incoming packet — before the kernel even knows whether to accept it. That hook placement is why Cilium can do line-rate load balancing and why some network filtering rules that look correct in iptables do nothing against certain traffic. The rules weren’t wrong. The hook was in the wrong place.
Next: XDP — packets processed before the kernel knows they arrived
Get EP07 in your inbox when it publishes → linuxcent.com/subscribe