eBPF: From Kernel to Cloud, Episode 7
What Is eBPF? · The BPF Verifier · eBPF vs Kernel Modules · eBPF Program Types · eBPF Maps · CO-RE and libbpf · XDP**
14 min read
Introduction
EP01 through EP06 covered what eBPF is, how the verifier keeps it safe, and how the toolchain compiles and loads programs across kernel versions. This episode is where that foundation meets production networking.
XDP — eXpress Data Path — is the earliest hook in the Linux kernel packet path. It fires before sk_buff allocation, before routing, before netfilter. A DROP decision at XDP costs one bounds check and a return value. Everything else is skipped. At 1 million packets per second, that difference shows up directly as CPU.
This episode explains where XDP sits, what it can and cannot see, how Cilium uses it, and what every Kubernetes operator needs to know about it — even if they never write an eBPF program.
Table of Contents
- TL;DR
- Quick Check: Is XDP Running on Your Cluster?
- Where XDP Sits in the Kernel Data Path
- XDP Modes
- The XDP Context: What Your Program Can See
- What This Means on Your Cluster Right Now
- XDP Metadata: Cooperating with TC
- How Cilium Uses XDP
- Operational Inspection
- Common Mistakes
- Key Takeaways
Architecture Overview
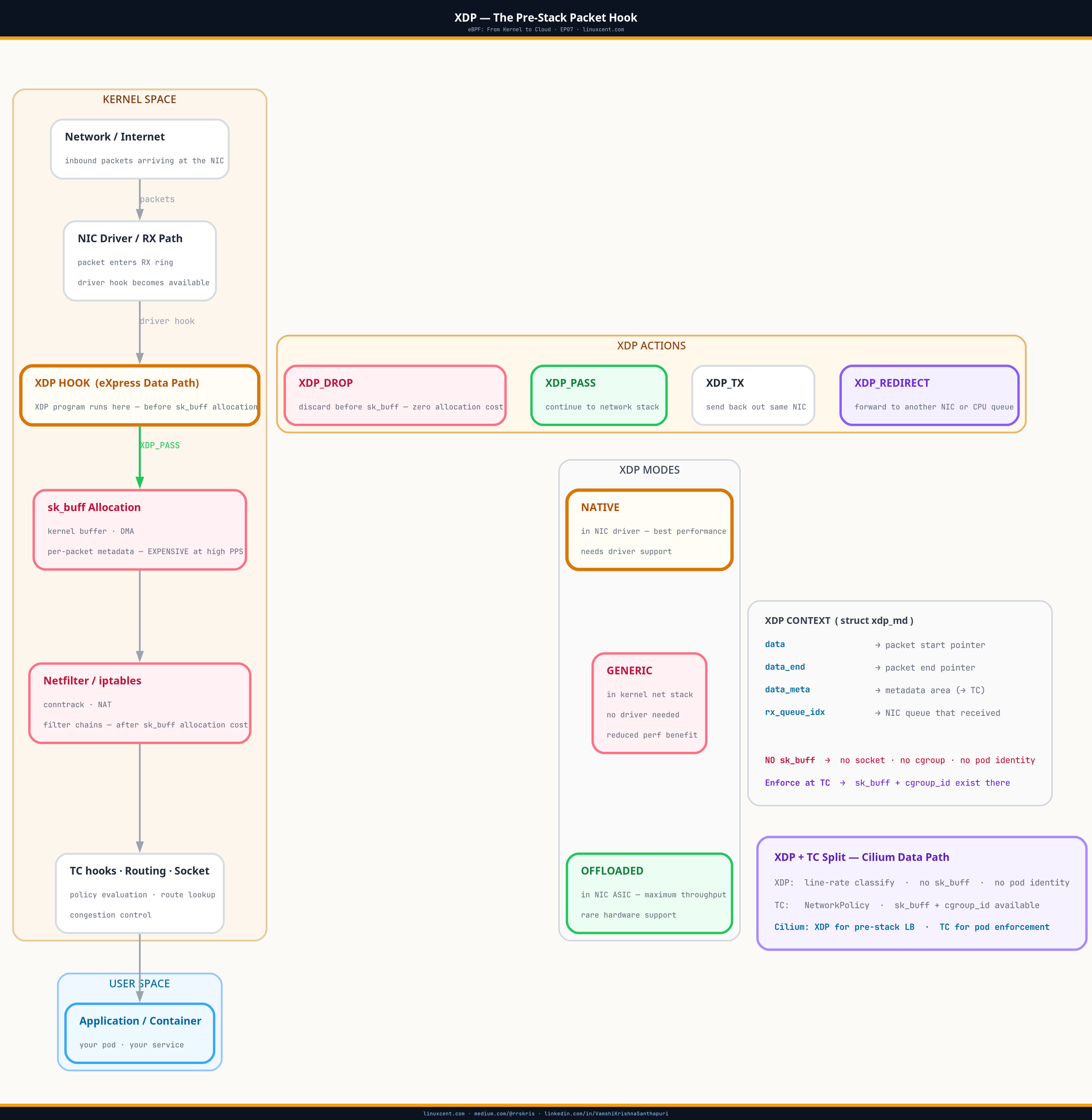
sk_buff allocation — the earliest possible kernel hook for zero-copy packet processing.TL;DR
- XDP fires before
sk_buffallocation — the earliest possible kernel hook for packet processing
(sk_buff= the kernel’s socket buffer — every normal packet requires one to be allocated, which adds up fast at scale) - Three modes: native (in-driver, full performance), generic (fallback, no perf gain), offloaded (NIC ASIC)
- XDP context is raw packet bytes — no socket, no cgroup, no pod identity; handle non-IP traffic explicitly
- Every pointer dereference requires a bounds check against
data_end— the verifier enforces this BPF_MAP_TYPE_LPM_TRIEis the right map type for IP prefix blocklists — handles /32 hosts and CIDRs together- XDP metadata area enables coordination with TC programs — classify at XDP speed, enforce with pod context at TC
Quick Check: Is XDP Running on Your Cluster?
Before the data path walkthrough — a two-command check you can run right now on any cluster node:
# SSH into a worker node, then:
bpftool net list
On a Cilium-managed node, you’ll see something like:
eth0 (index 2):
xdpdrv id 44
lxc8a3f21b (index 7):
tc ingress id 47
tc egress id 48
Reading the output:
– xdpdrv — XDP in native mode, running in the NIC driver before sk_buff (this is what you want)
– xdpgeneric instead of xdpdrv — generic mode, runs after sk_buff allocation, no performance benefit
– No XDP line at all — XDP not deployed; your CNI uses iptables for service forwarding
If you’re on EKS with aws-vpc-cni or GKE with kubenet, you likely won’t see XDP here — those CNIs use iptables. Understanding this section explains why teams migrating to Cilium see lower node CPU under the same traffic load.
Where XDP Sits in the Kernel Data Path
A client’s cluster was under a SYN flood — roughly 1 million packets per second from a rotating set of source IPs. We had iptables DROP rules installed within the first ten minutes, blocklist updated every 30 seconds as new source ranges appeared. The flood traffic dropped in volume. But node CPU stayed high. The %si column in top — software interrupt time — was sitting at 25–30%.
%siintopis the percentage of CPU time spent handling hardware interrupts and kernel-level packet processing — separate from your application’s CPU usage. On a quiet managed cluster (EKS, GKE) this is usually under 1%. Under a packet flood, high%simeans the kernel is burning cycles just receiving packets, before your workloads run at all. It’s the metric that tells you the problem is below the application layer.
The iptables rules were matching. Packets were being dropped. CPU was still burning. The answer is where in the kernel the drop was happening. iptables fires inside the netfilter framework — after the kernel has already allocated an sk_buff for the packet, done DMA from the NIC ring buffer, and traversed several netfilter hooks. At 1Mpps, the allocation cost alone is measurable.
XDP fires before any of that.
The standard Linux packet receive path:
NIC hardware
↓
DMA to ring buffer (kernel memory)
↓
[XDP hook — fires here, before sk_buff]
├── XDP_DROP → discard, zero further allocation
├── XDP_PASS → continue to kernel network stack
├── XDP_TX → transmit back out the same interface
└── XDP_REDIRECT → forward to another interface or CPU
↓
sk_buff allocated from slab allocator
↓
netfilter: PREROUTING
↓
IP routing decision
↓
netfilter: INPUT or FORWARD
↓ [iptables fires somewhere in here]
socket receive queue
↓
userspace application
XDP runs at the driver level, in the NAPI poll context — the same context where the driver is processing received packets off the ring buffer. The program runs before the kernel’s general networking code gets involved. There’s no sk_buff, no reference counting, no slab allocation.
NAPI (New API) is how modern Linux receives packets efficiently. Instead of one CPU interrupt per packet (catastrophically expensive at 1Mpps), the NIC fires a single interrupt, then the kernel polls the NIC ring buffer in batches until it’s drained. XDP runs inside this polling loop — as close to the hardware as software gets without running on the NIC itself.
At 1Mpps, the difference between XDP_DROP and an iptables DROP is roughly the cost of allocating and then immediately freeing 1 million sk_buff objects per second — plus netfilter traversal, connection tracking lookup, and the DROP action itself. That’s the CPU time that was burning.
After moving the blocklist to an XDP program, the %si on the same traffic load dropped from 28% to 3%.
XDP Modes
XDP operates in three modes, and which one you get depends on your NIC driver.
Native XDP (XDP_FLAGS_DRV_MODE)
The eBPF program runs directly in the NIC driver’s NAPI poll function — in interrupt context, before sk_buff. This is the only mode that delivers the full performance benefit.
Driver support is required. The widely supported drivers: mlx4, mlx5 (Mellanox/NVIDIA), i40e, ice (Intel), bnxt_en (Broadcom), virtio_net (KVM/QEMU), veth (containers). Check support:
# Verify native XDP support on your driver
ethtool -i eth0 | grep driver
# driver: mlx5_core ← supports native XDP
# Load in native mode
ip link set dev eth0 xdpdrv obj blocklist.bpf.o sec xdp
The veth driver supporting native XDP is what makes XDP meaningful inside Kubernetes pods — each pod’s veth interface can run an XDP program at wire speed.
Generic XDP (XDP_FLAGS_SKB_MODE)
Fallback for drivers that don’t support native XDP. The program still runs, but it runs after sk_buff allocation, as a hook in the netif_receive_skb path. No performance benefit over early netfilter. sk_buff is still allocated and freed for every packet.
# Generic mode — development and testing only
ip link set dev eth0 xdpgeneric obj blocklist.bpf.o sec xdp
Use this for development on a laptop with a NIC that lacks native XDP support. Never benchmark with it and never use it in production expecting performance gains.
Offloaded XDP
Runs on the NIC’s own processing unit (SmartNIC). Zero CPU involvement — the XDP decision happens in NIC hardware. Supported by Netronome Agilio NICs. Rare in production, but the theoretical ceiling for XDP performance.
The XDP Context: What Your Program Can See
XDP programs receive one argument: struct xdp_md.
struct xdp_md {
__u32 data; // offset of first packet byte in the ring buffer page
__u32 data_end; // offset past the last byte
__u32 data_meta; // metadata area before data (XDP metadata for TC cooperation)
__u32 ingress_ifindex;
__u32 rx_queue_index;
};
data and data_end are used as follows:
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
// Every pointer dereference must be bounds-checked first
struct ethhdr *eth = data;
if ((void *)(eth + 1) > data_end)
return XDP_PASS; // malformed or truncated packet
The verifier enforces these bounds checks — every pointer derived from ctx->data must be validated before use. The error invalid mem access 'inv' means you dereferenced a pointer without checking the bounds. This is the most common cause of XDP program rejection.
For operators (not writing XDP code): You’ll see
invalid mem access 'inv'in logs when an eBPF program is rejected at load time — most commonly during a Cilium upgrade or a custom tool deployment on a kernel the tool wasn’t built for. The fix is in the eBPF source or the tool version, not the cluster config.
What XDP cannot see:
– Socket state — no socket buffer exists yet
– Cgroup hierarchy — no pod identity
– Process information — no PID, no container
– Connection tracking state (unless you maintain it yourself in a map)
XDP is ingress-only. It fires on packets arriving at an interface, not departing. For egress, TC is the hook.
What This Means on Your Cluster Right Now
Every Cilium-managed node has XDP programs running. Here’s how to see them:
# All XDP programs on all interfaces — this is the full picture
bpftool net list
# Sample output on a Cilium node:
#
# eth0 (index 2):
# xdpdrv id 44 ← XDP in native mode on the node uplink
#
# lxc8a3f21b (index 7):
# tc ingress id 47 ← TC enforces NetworkPolicy on pod ingress
# tc egress id 48 ← TC enforces NetworkPolicy on pod egress
#
# "xdpdrv" = native mode (runs in NIC driver, before sk_buff — full performance)
# "xdpgeneric" = fallback mode (after sk_buff — no performance benefit over iptables)
# Which mode is active?
ip link show eth0 | grep xdp
# xdp mode drv ← native (full performance)
# xdp mode generic ← fallback (no perf benefit)
# Details on the XDP program ID
bpftool prog show id $(bpftool net show dev eth0 | grep xdp | awk '{print $NF}')
# Shows: loaded_at, tag, xlated bytes, jited bytes, map IDs
The map IDs in that output are the BPF maps the XDP program is using — typically the service VIP table for DNAT, and in security tools, the blocklist or allowlist. To see what’s in them:
# List maps used by the XDP program
bpftool prog show id <PROG_ID> | grep map_ids
# Dump the service map (for a Cilium node — this is the load balancer table)
bpftool map dump id <MAP_ID> | head -40
For a blocklist scenario — like the SYN flood mitigation above — the BPF_MAP_TYPE_LPM_TRIE is the standard data structure. A lookup for 192.168.1.45 hits a 192.168.1.0/24 entry in the same map, handling both host /32s and CIDR ranges in one lookup.
# Count entries in an XDP filter map
bpftool map dump id <BLOCKLIST_MAP_ID> | grep -c "key"
# Verify XDP is active and inspect program details
bpftool net show dev eth0
XDP Metadata: Cooperating with TC
Think of it as a sticky note attached to the packet. XDP writes the note at line speed (no context about pods or sockets). TC reads it later when full context is available, and acts on it. The packet carries the note between them.
More precisely: XDP can write metadata into the area before ctx->data — a small scratch space that survives as the packet moves from XDP to the TC hook. This is the coordination mechanism between the two eBPF layers.
The pattern: XDP classifies at speed (no sk_buff overhead), TC enforces with pod context (where you have socket identity). XDP writes a classification tag into the metadata area. TC reads it and makes the policy decision.
From an operational standpoint, when you see two eBPF programs on the same interface (one XDP, one TC), this pipeline is the likely explanation:
bpftool net list
# xdpdrv id 44 on eth0 ← XDP classifier running at line rate
# tc ingress id 47 on eth0 ← TC enforcer reading XDP metadata
How Cilium Uses XDP
Not running Cilium? On EKS with
aws-vpc-cnior GKE withkubenet, service forwarding uses iptables NAT rules andconntrackinstead. You can see this withiptables -t nat -L -non a node — look for theKUBE-SVC-*chains. Those chains are what XDP replaces in a Cilium cluster. This is why teams migrating from kube-proxy to Cilium report lower node CPU at high connection rates — it’s not magic, it’s hook placement.
On a Cilium node, XDP handles the load balancing path for ClusterIP services. When a packet arrives at the node destined for a ClusterIP:
- XDP program checks the destination IP against a BPF LRU hash map of known service VIPs
- On a match, it performs DNAT — rewriting the destination IP to a backend pod IP
- Returns
XDP_TXorXDP_REDIRECTto forward directly
No iptables NAT rules. No conntrack state machine. No socket buffer allocation for the routing decision. The lookup is O(1) in a BPF hash map.
# See Cilium's XDP program on the node uplink
ip link show eth0 | grep xdp
# xdp (attached, native mode)
# The XDP program details
bpftool prog show pinned /sys/fs/bpf/cilium/xdp
# Load time, instruction count, JIT-compiled size
bpftool prog show id $(bpftool net list | grep xdp | awk '{print $NF}')
At production scale — 500+ nodes, 50k+ services — removing iptables from the service forwarding path with XDP reduces per-node CPU utilization measurably. The effect is most visible on nodes handling high connection rates to cluster services.
Operational Inspection
# All XDP programs on all interfaces
bpftool net list
# Check XDP mode (native, generic, offloaded)
ip link show | grep xdp
# Per-interface stats — includes XDP drop/pass counters
cat /sys/class/net/eth0/statistics/rx_dropped
# XDP drop counters exposed via bpftool
bpftool map dump id <stats_map_id>
# Verify XDP is active and show program details
bpftool net show dev eth0
Common Mistakes
| Mistake | Impact | Fix |
|---|---|---|
| Missing bounds check before pointer dereference | Verifier rejects: “invalid mem access” | Always check ptr + sizeof(*ptr) > data_end before use |
| Using generic XDP for performance testing | Misleading numbers — sk_buff still allocated | Test in native mode only; check ip link output for mode |
| Not handling non-IP traffic (ARP, IPv6, VLAN) | ARP breaks, IPv6 drops, VLAN-tagged frames dropped | Check eth->h_proto and return XDP_PASS for non-IP |
| XDP for egress or pod identity | No socket context at XDP; XDP is ingress only | Use TC egress for pod-identity-aware egress policy |
Forgetting BPF_F_NO_PREALLOC on LPM trie |
Full memory allocated at map creation for all entries | Always set this flag for sparse prefix tries |
| Blocking ARP by accident in a /24 blocklist | Loss of layer-2 reachability within the blocked subnet | Separate ARP handling before the IP blocklist check |
Key Takeaways
- XDP fires before
sk_buffallocation — the earliest possible kernel hook for packet processing - Three modes: native (in-driver, full performance), generic (fallback, no perf gain), offloaded (NIC ASIC)
- XDP context is raw packet bytes — no socket, no cgroup, no pod identity; handle non-IP traffic explicitly
- Every pointer dereference requires a bounds check against
data_end— the verifier enforces this BPF_MAP_TYPE_LPM_TRIEis the right map for IP prefix blocklists — handles /32 hosts and CIDRs together- XDP metadata area enables coordination with TC programs — classify at XDP speed, enforce with pod context at TC
What’s Next
XDP handles ingress at the fastest possible point but has no visibility into which pod sent a packet. EP08 covers TC eBPF — the hook that fires after sk_buff allocation, where socket and cgroup context exist.
TC is how Cilium implements pod-to-pod network policy without iptables. It’s also where stale programs from failed Cilium upgrades leave ghost filters that cause intermittent packet drops. Knowing how TC programs chain — and how to find and remove stale ones — is a specific, concrete operational skill.
Next: TC eBPF — pod-level network policy without iptables
Get EP08 in your inbox when it publishes → linuxcent.com/subscribe