eBPF: From Kernel to Cloud, Episode 8
What Is eBPF? · The BPF Verifier · eBPF vs Kernel Modules · eBPF Program Types · eBPF Maps · CO-RE and libbpf · XDP · TC eBPF**
Architecture Overview
TL;DR
- TC eBPF fires after
sk_buffallocation — it has socket metadata, cgroup ID, and pod identity that XDP lacks
(sk_buff= the kernel’s socket buffer, allocated for every packet; TC fires after this allocation, so it can read socket and process identity) - Direct action (DA) mode combines filter and action; the program’s return value is the packet fate
- Multiple TC programs chain on the same hook ordered by priority — stale programs from Cilium upgrades cause silent policy conflicts
tc filter show dev <iface> ingress/egressis the primary inspection tool;bpftool net listshows the full node picture- XDP + TC is the Cilium data path: XDP for pre-stack service load balancing, TC for per-pod identity-based enforcement
- TC can modify packet content (
bpf_skb_store_bytes) — the basis for TC-based DNAT and packet mangling
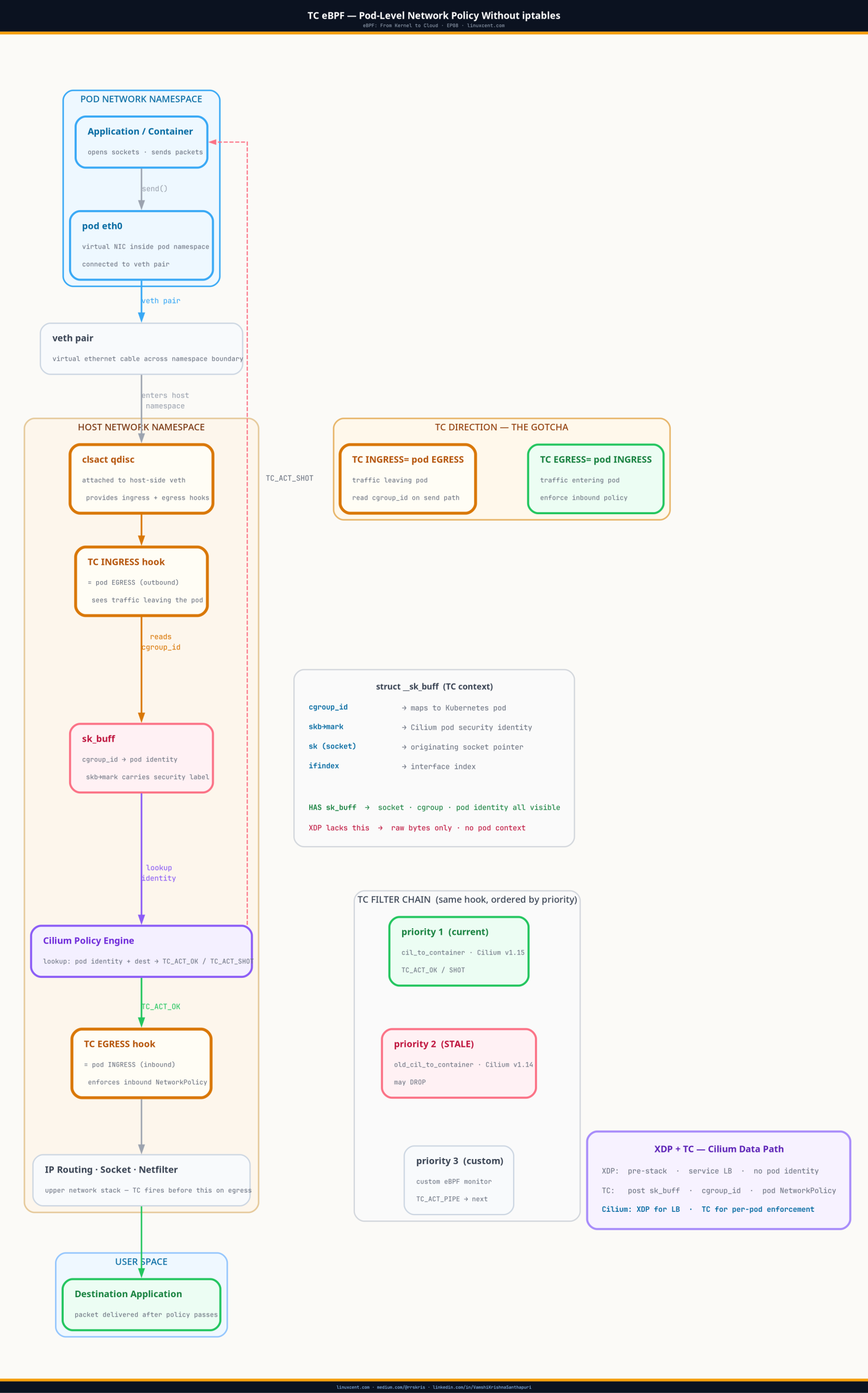
TC eBPF is where Cilium implements pod-level network policy without iptables — the hook that fires after sk_buff allocation, where socket and cgroup context exist, making per-pod enforcement possible. The obvious follow-up to XDP is why Cilium doesn’t use it for everything — pod network policy, egress enforcement, the full NetworkPolicy ruleset. The answer reveals an inherent trade-off built into the Linux data path: XDP’s speed comes from running before any context exists. At the moment it fires, there is no socket, no cgroup, no way to tell which pod sent the packet. The moment you need pod identity, you need a hook that fires later — and pays for it.
A specific pod in production was experiencing intermittent TCP connection failures to an external service. Not all connections — roughly one in fifty. Kubernetes NetworkPolicy showed egress allowed for the namespace. Cilium policy status showed no violations. Running curl from inside the pod worked fine.
The application logs told a different story: connection timeouts at the 30-second mark, no SYN-ACK received. Not a DNS issue — I verified with tcpdump inside the pod namespace. SYN packets were leaving the pod network namespace. They weren’t making it onto the wire.
I ran bpftool net list on the node and saw two TC egress programs attached to that pod’s veth interface. One from the current Cilium version (installed six weeks ago). One from the previous version — from before the rolling upgrade. Two programs. Different policy epochs. The older one had a stale block rule that fired intermittently based on connection tuple patterns it was never designed to handle in the new policy model.
Without understanding TC eBPF — what programs attach where, how multiple programs interact, and how to inspect them — I would have kept chasing ghosts in the application layer.
Quick Check: Are There Stale TC Filters on Your Cluster?
The most common TC eBPF issue on production clusters — stale filters left behind by a Cilium upgrade — is a two-command check:
# SSH into a worker node, then pick any pod's veth interface:
ip link | grep lxc | head -5
# lxc8a3f21b@if7: ...
# lxc2c9d3e1@if9: ...
# Check TC filters on that interface
tc filter show dev lxc8a3f21b egress
Healthy output (one filter, one priority):
filter protocol all pref 1 bpf chain 0
filter protocol all pref 1 bpf chain 0 handle 0x1 cil_to_container direct-action not_in_hw id 44
Stale filter present (two priorities = problem):
filter protocol all pref 1 bpf chain 0
filter protocol all pref 1 bpf chain 0 handle 0x1 cil_to_container direct-action not_in_hw id 44
filter protocol all pref 2 bpf chain 0
filter protocol all pref 2 bpf chain 0 handle 0x1 old_cil_to_container direct-action not_in_hw id 17
# ^^^^^^ two different priorities = two programs running in sequence
Two priorities on the same hook means two programs running sequentially. If the older one has a stale DROP rule, packets are being dropped intermittently — and nothing in the application layer will tell you why.
Not running Cilium? If you’re on a non-Cilium CNI (Calico, Flannel,
aws-vpc-cni), you likely won’t have TC eBPF filters on pod interfaces. Runtc filter show dev eth0 ingresson the node uplink instead to see if any TC programs are attached at the node level. An empty response is normal for non-Cilium clusters.
Why TC, Not XDP
EP07 covered XDP: fastest possible hook, fires before sk_buff, drops at line rate. If XDP is so fast, why doesn’t Cilium use it for everything?
Because XDP sees only raw packet bytes. No socket. No cgroup. No pod identity.
In Kubernetes, network policy is inherently about identity. “Allow pod A to connect to pod B on port 8080.” To enforce this, you need to know which pod a packet is coming from on egress — and which pod it’s going to on ingress. That mapping lives in the cgroup hierarchy and the socket buffer, neither of which exist at XDP time.
TC fires later in the packet lifecycle, after sk_buff is allocated and populated:
Ingress path:
wire → NIC → [XDP hook] → sk_buff allocated → [TC ingress hook] → netfilter → socket
Egress path:
socket → IP routing → [TC egress hook] → qdisc → NIC → wire
At the TC egress hook on a pod’s veth interface, the sk_buff carries the socket that created the packet — and from that socket you can read the cgroup ID. The cgroup hierarchy maps container → pod, so the TC program knows which pod this traffic belongs to. That’s what makes pod-level enforcement possible.
The Linux Traffic Control Architecture
tc (traffic control) is the Linux subsystem for managing packet queues and scheduling. Most Linux administrators know it as the bandwidth-shaping tool:
# Classic tc usage — rate limit an interface
tc qdisc add dev eth0 root tbf rate 100mbit burst 32kbit latency 400ms
The qdisc (queuing discipline) is the primary abstraction. Under the qdisc sits a filter layer — and the filter type relevant to eBPF is cls_bpf, which attaches eBPF programs as packet classifiers.
qdisc (queuing discipline) is the kernel’s packet scheduler for an interface — it controls how packets are buffered and in what order they leave. For eBPF policy enforcement, Cilium uses a special qdisc called
clsactwhich has no buffering behaviour at all; it purely provides the ingress and egress hook points where eBPF filters attach. If a pod veth doesn’t haveclsact, Cilium isn’t enforcing policy on that pod.
Cilium attaches cls_bpf filters in direct action (DA) mode, which combines classifier and action into a single eBPF program. The program’s return value is the packet fate directly:
| Return value | Action |
|---|---|
TC_ACT_OK (0) |
Pass the packet |
TC_ACT_SHOT (2) |
Drop the packet |
TC_ACT_REDIRECT (7) |
Redirect to another interface |
TC_ACT_PIPE (3) |
Pass to the next filter in the chain |
TC Context: What Your Program Can See
TC programs receive a struct __sk_buff — a safe, BPF-accessible projection of the kernel sk_buff. Unlike the raw packet bytes in XDP, __sk_buff includes metadata:
struct __sk_buff {
__u32 len; // packet length
__u32 pkt_type; // PACKET_HOST, PACKET_BROADCAST, etc.
__u32 mark; // skb->mark — used by Cilium for pod identity
__u32 queue_mapping;
__u32 protocol; // ETH_P_IP, ETH_P_IPV6, etc.
__u32 vlan_present;
__u32 vlan_tci;
__u32 vlan_proto;
__u32 priority;
__u32 ingress_ifindex;
__u32 ifindex;
__u32 tc_index;
__u32 cb[5];
__u32 hash;
__u32 tc_classid;
__u32 data; // offset to packet data
__u32 data_end;
__u32 napi_id;
__u32 family;
__u32 remote_ip4; // source IP (ingress) or dest IP (egress)
__u32 local_ip4;
__u32 remote_port;
__u32 local_port;
// ...
};
skb->mark is how Cilium passes pod identity between its hook points.
skb->markis a 32-bit field in everysk_buffthat any kernel subsystem can read or write. It’s a general-purpose scratch field — iptables uses it, routing rules use it, and Cilium uses it to carry pod security identity from the socket hook through to TC enforcement. When Cilium stamps a pod’s identity intoskb->markat connection time, every subsequent TC filter on that packet’s path can read it without another identity lookup. The socket-level cgroup hook (cgroup_sock_addr) stamps the cgroup-derived pod identity intoskb->markwhen the socket callsconnect(). By the time the packet reaches the TC egress hook,skb->markcarries the pod’s security identity — and the TC program uses it for policy enforcement.
What Cilium’s TC Filters Actually Do
The TC filter on each pod’s veth is Cilium’s enforcement point for Kubernetes NetworkPolicy. The mechanism:
- When a pod opens a connection, a
cgroup_sock_addrhook stamps the pod’s security identity (derived from its labels + namespace) intoskb->mark - The TC egress filter on the veth reads
skb->mark, looks up the pod identity + destination in the policy map, and returnsTC_ACT_SHOT(drop) orTC_ACT_OK(pass) - The TC ingress filter on the receiving pod’s veth does the same check for inbound traffic
The policy map is a BPF LRU hash keyed on {pod_identity, dst_ip, dst_port, protocol}. This is what cilium policy get reads from — and what bpftool map dump shows directly:
# Find Cilium's policy maps
bpftool map list | grep -i policy
# Dump the active policy entries for a specific endpoint
# Get endpoint ID from: cilium endpoint list
cilium bpf policy get <endpoint-id>
# Cross-check with raw bpftool dump
bpftool map dump id <POLICY_MAP_ID> | head -30
The clsact qdisc is the prerequisite for any TC eBPF filter — it creates the ingress and egress hook points without any queuing behavior. Every pod veth on a Cilium node has one:
tc qdisc show dev lxcABCDEF
# qdisc clsact ffff: dev lxcABCDEF parent ffff:fff1
# ^^^^^^^^^^^^ this line confirms Cilium's hook points exist on this pod's veth
# If this is missing: Cilium is NOT enforcing NetworkPolicy on this pod
If a pod veth doesn’t show clsact, Cilium isn’t enforcing policy on that pod.
Multiple Programs and the Filter Chain
This is the detail that caused my production incident.
TC supports chaining multiple filters on the same hook, ordered by priority. Lower priority number runs first. When Cilium upgrades, it installs a new filter at a new priority before removing the old one. If the upgrade procedure has any timing gap — or if the removal step fails silently — you end up with two programs running in sequence.
# Show all TC filters on a pod's veth — both priorities visible
tc filter show dev lxc12345 egress
# Example output with a stale filter:
filter protocol all pref 1 bpf chain 0
filter protocol all pref 1 bpf chain 0 handle 0x1 cil_to_container direct-action not_in_hw id 44
filter protocol all pref 2 bpf chain 0
filter protocol all pref 2 bpf chain 0 handle 0x1 old_cil_to_container direct-action not_in_hw id 17
Two programs. Pref 1 runs first. Pref 2 runs second — unless pref 1 returned TC_ACT_SHOT, in which case the packet is already dropped and pref 2 never fires.
In my incident: pref 1 was the current Cilium version with correct policy, returning TC_ACT_OK for the traffic in question. Pref 2 was the old version with a stale block entry, returning TC_ACT_SHOT for a subset of connection tuples. Because TC_ACT_OK passes to the next filter in the chain (TC_ACT_PIPE would do the same), pref 2 got to run — and intermittently dropped packets.
The fix:
# Remove the stale filter by priority
tc filter del dev lxc12345 egress pref 2
# Verify only the current filter remains
tc filter show dev lxc12345 egress
This should be part of any post-upgrade verification for Cilium-managed clusters.
How Cilium Uses TC Across the Full Node
Cilium’s TC deployment on a node:
Pod veth (host-side, lxcXXXXX):
TC ingress: cil_from_container — L3/L4 policy on the pod's outbound traffic
TC egress: cil_to_container — L3/L4 policy on traffic arriving at the pod
Node uplink (eth0):
TC ingress: cil_from_netdev — traffic arriving from outside the node
TC egress: cil_to_netdev — traffic leaving the node
XDP on eth0:
cil_xdp_entry — pre-stack service load balancing (DNAT for ClusterIP)
The naming is counterintuitive at first: cil_from_container is attached to the TC ingress hook on the veth.
Veth direction confusion: TC ingress/egress is named from the kernel’s perspective of the interface, not the pod’s. The host-side veth interface receives traffic that the pod is sending — so TC ingress on the host veth = the pod’s outbound traffic. This trips up everyone the first time. When debugging, always confirm direction with
tc filter show dev lxcXXX ingressandegressseparately, and check which Cilium program name is attached (cil_from_container= pod outbound,cil_to_container= pod inbound). The veth ingress direction from the host perspective is traffic flowing out of the container. Traffic leaving the pod hits the host-side veth ingress, which iscil_from_container. It enforces egress policy for the pod. Naming follows the kernel’s perspective of the interface, not the application’s.
To see the full picture on a node:
# All eBPF network programs (XDP and TC) across all interfaces
bpftool net list
# TC-specific view
for iface in $(ip link | grep lxc | awk -F': ' '{print $2}'); do
echo "=== $iface ==="
tc filter show dev $iface ingress
tc filter show dev $iface egress
done
TC Can Modify Packets Too
Unlike XDP, TC programs have full access to the sk_buff and can modify packet content — headers, payload, and checksums. This is how TC-based DNAT works in Cilium when XDP isn’t available on the NIC: the program rewrites the destination IP at L3 and updates the IP + transport checksums atomically. The kernel BPF helper handles the checksum recalculation.
From an operational standpoint: if you see a TC program attached but expected traffic is being redirected rather than dropped, the program is likely doing DNAT. bpftool prog dump xlated id <ID> shows the disassembled instructions and will reveal bpf_skb_store_bytes calls if packet rewriting is happening.
Debugging TC Programs in Production
Workflow I follow when investigating network issues on Cilium clusters:
# 1. List all eBPF network programs (see the full picture)
bpftool net list
# 2. Check specific interface for stale TC filters
tc filter show dev lxcABCDEF ingress
tc filter show dev lxcABCDEF egress
# 3. Inspect a specific program
bpftool prog show id 44
# 4. Disassemble a program (last resort for understanding behavior)
bpftool prog dump xlated id 44
# 5. Check Cilium's view of the same interface
cilium endpoint list
cilium endpoint get <endpoint-id>
# 6. Enable verbose TC program logs (debug builds only)
# Cilium: set CILIUM_DEBUG=true in the deployment
Common Mistakes
| Mistake | Impact | Fix |
|---|---|---|
| Not checking for stale TC filters after Cilium upgrades | Conflicting policy programs cause intermittent drops | Run tc filter show post-upgrade; remove stale by priority |
| Confusing ingress/egress direction on veth interfaces | Policy applied to wrong traffic direction | TC ingress on host-side veth = pod’s outbound traffic |
Attaching TC without clsact qdisc |
Filter attachment fails | tc qdisc add dev <iface> clsact before filter add |
Using TC_ACT_OK when you want to stop the chain |
Subsequent filters still run | Use TC_ACT_OK knowing the chain continues; use TC_ACT_REDIRECT or explicit TC_ACT_SHOT only |
| Expecting TC performance equal to XDP | TC has sk_buff overhead — it’s slower | Right tool: XDP for pre-stack bulk drops, TC for identity-aware policy |
Hardcoding skb->mark interpretation |
Different tools use mark differently | Document mark field usage clearly; coordinate between Cilium and custom programs |
Key Takeaways
- TC eBPF fires after
sk_buffallocation — it has socket metadata, cgroup ID, and pod identity that XDP lacks - Direct action (DA) mode combines filter and action; the program’s return value is the packet fate
- Multiple TC programs chain on the same hook ordered by priority — stale programs from Cilium upgrades cause silent policy conflicts
tc filter show dev <iface> ingress/egressis the primary inspection tool;bpftool net listshows the full node picture- XDP + TC is the Cilium data path: XDP for pre-stack service load balancing, TC for per-pod identity-based enforcement
- TC can modify packet content (
bpf_skb_store_bytes) — the basis for TC-based DNAT and packet mangling
What’s Next
EP08 closes out the kernel machinery arc: program types, maps, CO-RE, XDP, TC. Five episodes on the engine under the tools. EP09 shifts from understanding the machinery to using it interactively.
bpftrace turns kernel knowledge into one-liners you can run on a live production node. Which process is touching this file right now? Where is this latency spike originating in the kernel call stack? Which container is making DNS queries to an unexpected resolver? Under 10 seconds per question — no restart, no sidecar, no instrumentation change.
Every bpftrace one-liner is a complete eBPF program compiled, loaded, run, and cleaned up on the fly. EP09 covers how that works and why it changes the way you investigate production incidents.
Next: bpftrace — kernel answers in one line
Get EP09 in your inbox when it publishes → linuxcent.com/subscribe