Reading Time: 6 minutes
~1,900 words · Reading time: 7 min · Series: eBPF: From Kernel to Cloud, Episode 1 of 18
Your Linux kernel has had a technology built into it since 2014 that most engineers working with Linux every day have never looked at directly. You have almost certainly been using it — through Cilium, Falco, Datadog, or even systemd — without knowing it was there.
This post is the plain-English introduction to eBPF that I wished existed when I first encountered it. No kernel engineering background required. No bytecode, no BPF maps, no JIT compilation. Just a clear answer to the question every Linux admin and DevOps engineer eventually asks: what actually is eBPF, and why does it matter for the infrastructure I run every day?
Architecture Overview
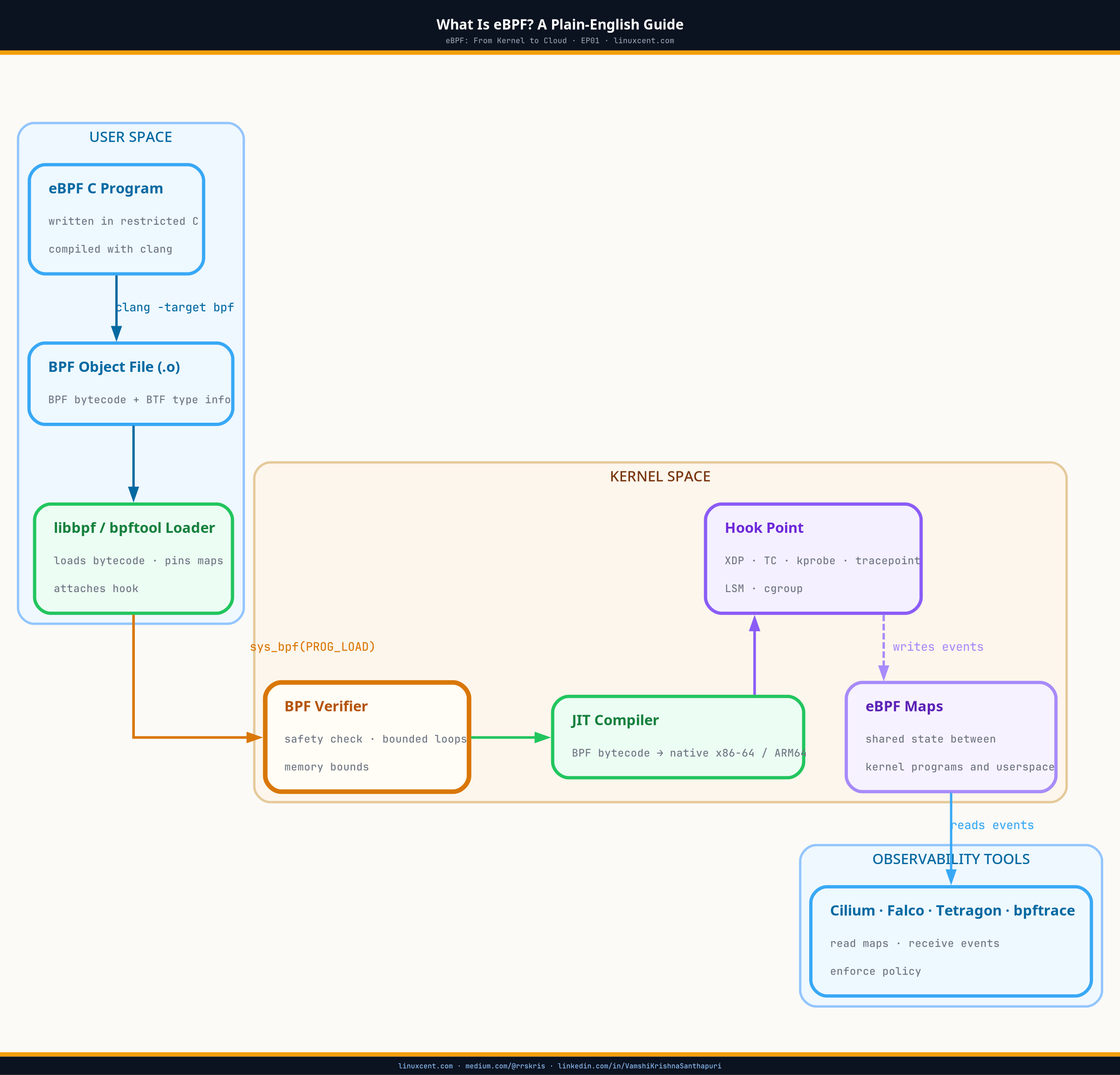
TL;DR
- eBPF lets you run small, safe programs inside the Linux kernel — no kernel module, no reboot, no application changes required
- The name is a historical artefact; modern eBPF is a general-purpose kernel observability and networking platform, not a packet filter
- Programs attach to kernel hook points (tracepoints, kprobes, socket filters) — giving you visibility into every syscall, file open, and network packet
- You are probably already running eBPF: Cilium, Falco, Datadog, and systemd all use it under the hood
- Safe for production because the BPF verifier rejects any program that could crash or loop — covered in depth in EP02
- Full feature set from Linux 5.8+; meaningful production use from Linux 4.14+ (most EKS and GKE defaults qualify)
First: Forget the Name
eBPF stands for extended Berkeley Packet Filter. It is one of the most misleading names in computing for what the technology actually does.
The original BPF was a 1992 mechanism for filtering network packets — the engine behind tcpdump. The extended version, introduced in Linux 3.18 (2014) and significantly matured through Linux 5.x, is a completely different technology. It is no longer just about packets. It is no longer just about filtering.
Forget the name. Here is what eBPF actually is:
eBPF lets you run small, safe programs directly inside the Linux kernel — without writing a kernel module, without rebooting, and without modifying your applications.
That is the complete definition. Everything else is implementation detail. The one-liner above is what matters for how you use it day to day.
What the Linux Kernel Can See That Nothing Else Can
To understand why eBPF is significant, you need to understand what the Linux kernel already sees on every server and every Kubernetes node you run.
The kernel is the lowest layer of software on your machine. Every action that happens — every file opened, every process started, every network packet sent — passes through the kernel. That means it has a complete, real-time view of everything:
- Every syscall — every
open(),execve(),connect(),write()from every process in every container on the node, in real time - Every network packet — source, destination, port, protocol, bytes, and latency for every pod-to-pod and pod-to-external connection
- Every process event — every fork, exec, and exit, including processes spawned inside containers that your container runtime never reports
- Every file access — which process opened which file, when, and with what permissions, across all workloads on the node simultaneously
- CPU and memory usage — per-process CPU time, function-level latency, and memory allocation patterns without profiling agents
The kernel has always had this visibility. The problem was that there was no safe, practical way to access it without writing kernel modules — which are complex, kernel version-specific, and genuinely dangerous to run in production. eBPF is the safe, practical way to access it.
The Problem eBPF Solves — A Real Kubernetes Scenario
Here is a situation every Kubernetes engineer has faced. A production pod starts behaving strangely — elevated CPU, slow responses, occasional connection failures. You want to understand what is happening at a low level: what syscalls is it making, what network connections is it opening, is something spawning unexpected processes?
The old approaches and their problems
Restart the pod with a debug sidecar. You lose the current state immediately. The issue may not reproduce. You have modified the workload.
Run strace inside the container via kubectl exec. strace uses ptrace, which adds 50–100% CPU overhead to the traced process and is unavailable in hardened containers. You are tracing one process at a time with no cluster-wide view.
Poll /proc with a monitoring agent. Snapshot-based. Any event that happens between polls is invisible. A process that starts, does something, and exits between intervals is completely missed.
The eBPF approach
# Use a debug pod on the node — no changes to your workload
$ kubectl debug node/your-node -it --image=cilium/hubble-cli
# Real-time kernel events from every container on this node:
sys_enter_execve pid=8821 comm=sh args=["/bin/sh","-c","curl http://..."]
sys_enter_connect pid=8821 comm=curl dst=203.0.113.42:443
sys_enter_openat pid=8821 comm=curl path=/etc/passwd
# Something inside the pod spawned a shell, made an outbound connection,
# and read /etc/passwd — all visible without touching the pod.Real-time visibility. No overhead on your workload. Nothing restarted. Nothing modified. That is what eBPF makes possible.
Tools You Are Probably Already Running on eBPF
eBPF is not a standalone product — it is the foundation that many tools in the cloud-native ecosystem are built on. You may already be running eBPF on your nodes without thinking about it explicitly.
| Tool | What eBPF does for it | Without eBPF |
|---|---|---|
| Cilium | Replaces kube-proxy and iptables with kernel-level packet routing. 2–3× faster at scale. | iptables rules — linear lookup, degrades with service count |
| Falco | Watches every syscall in every container for security rule violations. Sub-millisecond detection. | Kernel module (risky) or ptrace (high overhead) |
| Tetragon | Runtime security enforcement — can kill a process or drop a network packet at the kernel level. | No practical alternative at this detection speed |
| Datadog Agent | Network performance monitoring and universal service monitoring without application code changes. | Language-specific agents injected into application code |
| systemd | cgroup resource accounting and network traffic control on your Linux nodes. | Legacy cgroup v1 interfaces with limited visibility |
eBPF vs the Old Ways
Before eBPF, getting deep visibility into a running Linux system meant choosing between three approaches, each with a significant trade-off:
| Approach | Visibility | Cost | Production safe? |
|---|---|---|---|
| Kernel modules | Full kernel access | One bug = kernel panic. Version-specific, must recompile per kernel update. | No |
| ptrace / strace | One process at a time | 50–100% CPU overhead on the traced process. Unusable in production. | No |
| Polling /proc | Snapshots only | Events between polls are invisible. Short-lived processes are missed entirely. | Partial |
| eBPF | Full kernel visibility | 1–3% overhead. Verifier-guaranteed safety. Real-time stream, not polling. | Yes |
Is It Safe to Run in Production?
This is always the first question from any experienced Linux admin, and it is exactly the right question to ask. The answer is yes — and the reason is the BPF verifier.
Before any eBPF program is allowed to run on your node, the Linux kernel runs it through a built-in static safety analyser. This analyser examines every possible execution path and asks: could this program crash the kernel, loop forever, or access memory it should not?
If the answer is yes — or even maybe — the program is rejected at load time. It never runs.
This is fundamentally different from kernel modules. A kernel module loads immediately with no safety check. If it has a bug, you find out at runtime — usually as a kernel panic. An eBPF program that would cause a panic is rejected before it ever loads. The safety guarantee is mathematical, not hopeful.
Episode 2 of this series covers the BPF verifier in full: what it checks, how it makes Cilium and Falco safe on your production nodes, and what questions to ask eBPF tool vendors about their implementation.
Common Misconceptions
eBPF is not a specific tool or product. It is a kernel technology — a platform. Cilium, Falco, Tetragon, and Pixie are tools built on top of it. When a vendor says “we use eBPF”, they mean they build on this kernel capability, not that they share a single implementation.
eBPF is not only for networking. The Berkeley Packet Filter name suggests networking, but modern eBPF covers security, observability, performance profiling, and tracing. The networking origin is historical, not a limitation.
eBPF is not only for Kubernetes. It works on any Linux system running kernel 4.9+, including bare metal servers, Docker hosts, and VMs. K8s is the most popular deployment target because of the observability challenges at scale, but it is not a requirement.
You do not need to write eBPF programs to benefit from eBPF. Most Linux admins and DevOps engineers will use eBPF through tools like Cilium, Falco, and Datadog — never writing a line of BPF code themselves. This series covers the writing side later. Understanding what eBPF is makes you a significantly better user of these tools today.
Kernel Version Requirements
eBPF is a Linux kernel feature. The capabilities available depend directly on the kernel version running on your nodes. Run uname -r on any node to check.
| Kernel | What becomes available |
|---|---|
4.9+ |
Basic eBPF support. Tracing, socket filtering. Most production systems today meet this minimum. |
5.4+ |
BTF (BPF Type Format) and CO-RE — programs that adapt to different kernel versions without recompile. Recommended minimum for production tooling. |
5.8+ |
Ring buffers for high-performance event streaming. Global variables. The target kernel for Cilium, Falco, and Tetragon full feature support. |
6.x |
Open-coded iterators, improved verifier, LSM security enforcement hooks. Amazon Linux 2023 and Ubuntu 22.04+ ship 5.15 or newer and are fully eBPF-ready. |
EKS users: Amazon Linux 2023 AMIs ship with kernel 6.1+ and support the full modern eBPF feature set out of the box. If you are still on AL2, the migration also resolves the NetworkManager deprecation issues covered in the EKS 1.33 post.
The Bottom Line
eBPF is the answer to a question Linux engineers have been asking for years: how do I get deep visibility into what is happening on my servers and Kubernetes nodes — without adding massive overhead, injecting sidecars, or risking a kernel panic?
The answer is: run small, safe programs at the kernel level, where everything is already visible. Let the BPF verifier guarantee those programs are safe before they run. Stream the results to your observability tools through shared memory maps.
The tools you already use — Cilium for networking, Falco for security, Datadog for APM — are built on this foundation. Understanding eBPF means understanding why those tools work the way they do, what they can and cannot see, and how to evaluate new tools that claim to use it.
Every eBPF-based tool you run on your nodes passed through the BPF verifier before it touched your cluster. Episode 2 covers exactly what that means — and why it matters for your infrastructure decisions.
Further Reading
- ebpf.io — What is eBPF? (official introduction)
- Cilium documentation: eBPF dataplane explained
- Falco: kernel event sources and eBPF driver
- Isovalent: the story behind eBPF
- Brendan Gregg’s eBPF reference page
Questions or corrections? Reach me on LinkedIn. If this was useful, the full series index is on linuxcent.com — search the eBPF Series tag for all episodes.